
알쓸데이 : 모수
들어가며
안녕하세요, 반갑습니다.
숨고의 Data Scientist인 Furiosa입니다.
지난 알쓸데이 1편에 이어 새로운 주제로 찾아왔습니다. 알쓸데이 시리즈를 처음 접하는 분들을 위해 다시금 소개해 드리면 이 시리즈는 업무에서 사용하는 여러 통계적인 개념을 알기 쉽게 설명하는 것을 목표로 하고 있습니다. 더 자세한 내용은 1편을 참조해 주세요 (1편 : 알쓸데이 : 데이터 그리고 숫자)
두 번째 데이터 이야기 주제는 ‘모수’입니다.
모수는 제가 알쓸데이를 기획하게 만든 중요한 계기가 되었습니다. 데이터 전문가와 비전문가 등 다양한 배경을 가진 이해관계자들과 이야기하면서 제가 배웠던 ‘모수’의 정의가 실무에서는 다르게 사용하는 상황을 겪으면서 큰 괴리감을 느꼈고, 그로 인해 업무 과정에서 난감함을 느꼈던 상황이 있었기 때문입니다.
현업에 계신 분이라면, 아래와 같은 상황을 한 번쯤은 들어보셨으리라 생각합니다. 여기서 등장하는 모수는 무엇을 의미할까요?
-
우리 B군의 모수가 모자라서, 이 실험은 한 주 더 연장해야 할 것 같아요
-
우리 B군의 모수가 모자라서, 테스트의 신뢰도를 믿을 수 있을지 검토해 봐야 할 것 같아요
이 문장에서 ‘모수’는 뒤에서 이야기할 ‘표본’의 의미로 사용되고 있습니다. 이는 현업에서 많은 분들이 모수를 ‘모집단의 수’를 줄인 약어라고 생각하기 때문입니다. 물론 '모집단의 수' 라는 표현 역시 상당히 어색하다고 생각합니다. 이에 대해서는 이후 조금 더 자세하게 이야기 하겠습니다.
반대로 통계학에서 ‘모수’라는 단어를 먼저 접하신 분들이라면 영어식 표현인 ‘파라미터’가 더 친숙할 겁니다. 파라미터는 내가 관측하고 싶은 모집단의 특성을 나타내는 개념입니다.
앞선 문단에서 모집단, 표본, 파라미터 등 추상적인 통계적인 개념이 등장합니다. 이 개념에 친숙하지 않은 분들을 위해 각각에 대해서 먼저 설명한 뒤 모수에 대해 더 이야기를 해보겠습니다.
모집단, 그리고 표본
'모집단(population)'은 보통 우리가 관심을 가지는 대상입니다. 알기 쉽게 A/B 테스트를 기준으로 이야기해 보면, 앱 또는 웹을 사용하는 미래의 유저 집단이 보통 모집단이 됩니다. 하지만 쉬운 정의와는 다르게, 현실에서 모집단이라는 개념을 구체적으로 구현하는 것은 생각보다 어렵습니다.
숨고의 케이스로 보겠습니다. ‘숨고의 미래 유저들’ 을 어떻게 정의할 수 있을까요? 모든 한국인을 대상으로 하면 될까요? 아니면 생산 가능 인구로 한정하면 좋을까요? 만약, 한국인 모두가 대상이 된다면, 제한된 시간과 자원으로 모든 한국인을 조사할 수 있을까요? 미래 유저라고 했는데, 이후 새롭게 태어나는 사람들은 어떻게 조사할까요?
모집단의 핵심은 이것이 상당히 추상적인 개념이라는 점입니다. 데이터 분석을 위해서는 추상적인 개념들을 현실화시켜야 하는 과정이 필요합니다. 설사 모집단이 구체적으로 정의되더라도 제한된 시간과 자원으로 이 집단을 모두 조사하는 것이 현실적으로 불가능한 경우가 많습니다.
따라서, 대개 모집단을 대표하는 ‘표본(sample)’을 만들고 이를 분석하게 됩니다. 이 과정에서 모집단을 잘 대변하는 표본을 만드는 것이 중요하며, 이것이 샘플링 기법입니다. 흔히 사용되는 랜덤 샘플링이 이러한 샘플링 기법의 대표적인 방식입니다.
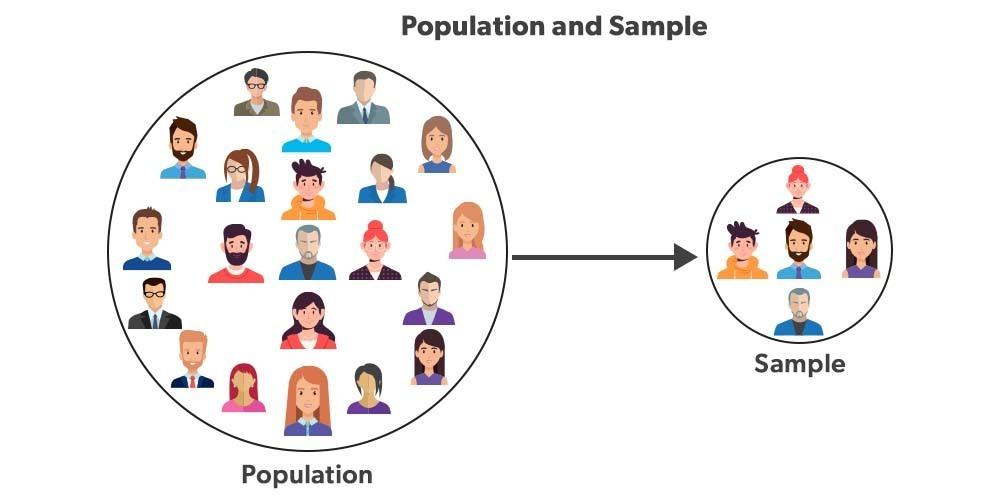
모집단은 아주 추상적인 개념이기에 ‘모집단의 수’는 보통 우리의 관심 대상이 아닙니다. 오히려 모집단을 제대로 대변하는 표본을 만드는 것에 관심이 있기에 표본의 수가 우리에게 중요합니다. 위의 이미지처럼 표본은 모집단의 하위 그룹이기에 표본이 계속 커지면 모집단이 됩니다. 하지만, 표본을 계속 늘리는 것은 시간과 자원의 한계로 제한될 수 밖에 없기 때문에 A/B 테스트 구조상 적절한 표본 수를 확보하는 것이 중요한 포인트가 됩니다.
따라서, 앞선 대화보다 정확한 전달을 위해서 위 문장에서 ‘모수’는 ‘표본 수’로 변경되는 것이 더 적절해 보입니다.
추가적으로 위 문장에서 모수를 ‘모집단의 수’라고, 해석하였을 때 모집단은 추상적일뿐더러 위에서 언급한 제약 때문에 모집단의 수를 측정한다는 것은 맞지 않고, 우리가 계산한 수는 모집단의 수도 아닙니다.
즉, 현업에서 ‘모집단의 수’로 해석하는 것도 의미상 맞지 않으며, 반대로 ‘파라미터’라고 해석하는 것은 더욱 이상합니다.
-
우리 B군 모수(→ 표본 수)가 모자라서, 이 실험 한 주 더 연장해야 할 것 같아요
-
우리 B군 모수(→표본 수)가 모자라서, 테스트의 신뢰도를 믿을 수 있을지 검토해 봐야 할 것 같아요
모수를 ‘모집단의 수’로 해석했을 때, 제가 가지는 의아함이 조금은 이해가 되셨나요? 이러한 관점에서 위의 문장 ‘모수’는 ‘표본 수’로 대체되는 것이 더 적절해 보입니다.
모수, 그리고 추정량
그렇다면, ‘모수'는 어떻게 사용하는 것이 정확할까요?
통계적으로 ‘모수’는 우리가 분석하고 싶은 모집단의 특성을 의미합니다. 추상적인 내용이라, 구체적인 A/B 테스트를 예시로 들어보겠습니다. 전환율 실험을 하였을 때, 우리가 관심을 가지는 것은 어떠한 액션을 A에서 B로 변경하였을 때 우리의 미래 유저 집단에게 유효한 변화를 일으키는 것인가입니다.
여기서 모집단은 숨고 미래 유저 집단이 되고, 관심을 가지는 모집단의 특성, 즉 모수는 A 액션의 결과와 B 액션의 결과 차이라고 해석할 수 있습니다. 하지만 누차 강조하였듯이 모집단은 추상적이기에 정의하기 어렵고, 정의되더라도 자원의 한계상 관측하기가 쉽지 않습니다. 따라서 A 액션을 한 표본 A 그룹과 B 액션을 한 표본 B 그룹 두 샘플 집단을 비교하는 형태로 테스트하게 됩니다.
이것이 일반적인 A/B 테스트의 구조입니다. A 그룹 표본과 B 그룹의 표본이 제대로 구현되었다는 전제로 이는 각각 미래 유저 집단을 대표하게 됩니다.
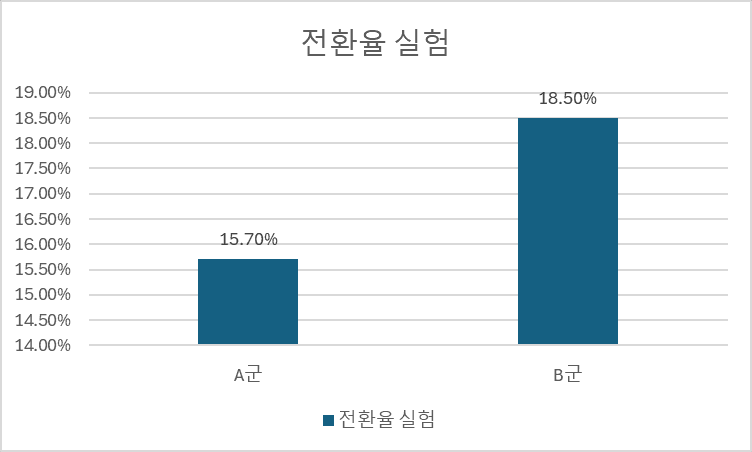
각각에 대해서 위와 같은 결과를 얻었다고 가정해 보겠습니다. A군의 결과 15.7% (), B군의 결과 18.5% () 는 유효한 차이라고 볼 수 있나요? 1편에서 이야기했던 것처럼 이를 위해서는 통계적인 검정 과정을 거쳐야 하며, 통계적 검정 결과 유의미하다는 것은 이것이 ‘모집단에서도 차이가 난다’고 해석할 수 있습니다. 실제로 테스트에 사용된 은 추정량 (estimator) 이라고 합니다.
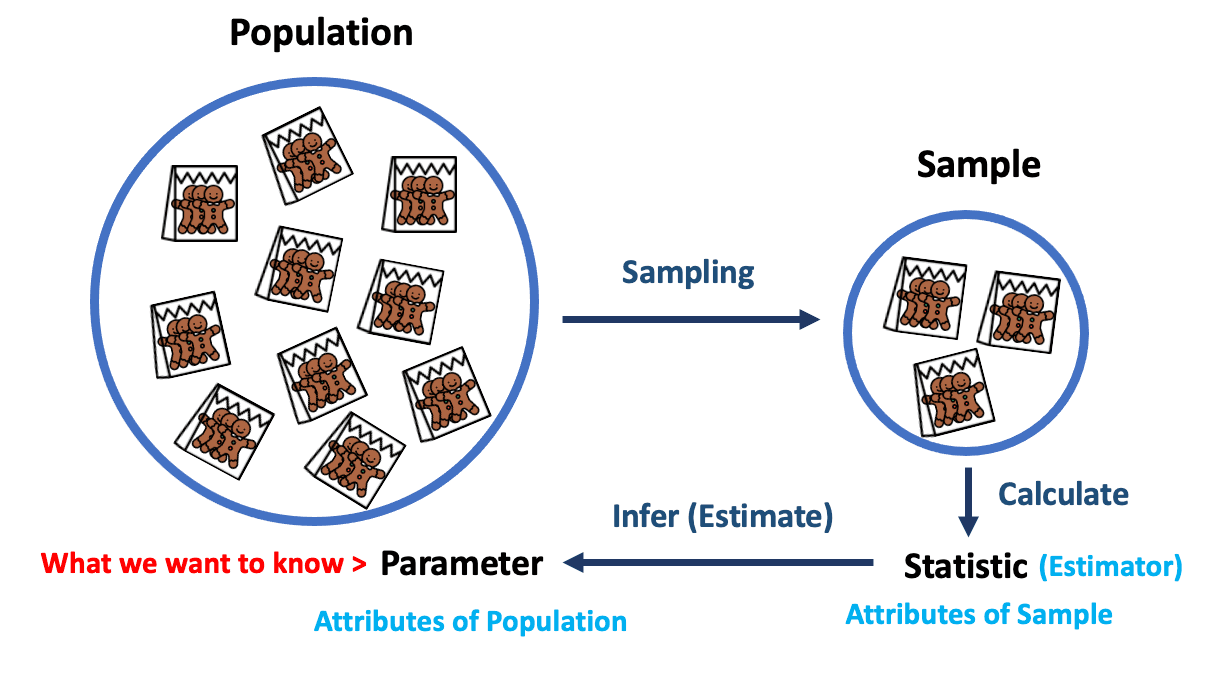
이를 요약하자면, 위의 그림과 같습니다. 모집단은 상당히 추상적이고 현실적으로 구현되기가 어렵기에 우리는 그를 잘 대변하는 그룹인 표본을 수집합니다. 그리고 표본에서 계산된 추정량과 우리가 관심을 가지는 모집단의 특성인 모수를 비교하는 작업을 하게 되고, 이 과정을 보통 통계적 추론이라고 합니다.
더 정확한 용어의 이점
단어의 사용은 동음이의어처럼 꼭 한 가지 의미만 가져야 하는 것은 아닙니다. 그러나 높은 수준의 데이터 리터러시를 가진 조직의 특징 중 하나는 정확한 통계 용어 사용에 대한 전사 차원의 공감대가 있다는 것입니다.
정확한 통계 용어는 당연하게도 통계적인 베이스에 기반해야 합니다. 왜냐하면, 이것이 더 보편적인 정의, 즉 사람들이 더 많이 동의한 정의이기 때문입니다. 이를 통해 조직은 내외부 커뮤니케이션 비용을 감소시킬 것으로 기대됩니다.
이 글을 읽은 분들만큼은 “우리가 사용하는 모수라는 단어의 사용 방법이 정말 적절한가?”라는 의구심을 가졌으면 좋겠습니다. 만약, 이 작은 계기를 만들었다면, 제 글은 목표를 달성한 것으로 생각합니다.
그럼 저는 흥미로운 데이터 이야기로 다음 시리즈에서 찾아오겠습니다. 긴 글 읽어주셔서 감사합니다.
출처
- #data
- #data-driven
- #data-driven decision making
- #data-driven organization
- #start up
- #statistics
- #data literacy



