
알쓸데이 : 데이터 그리고 숫자
들어가며
안녕하세요, 숨고 Data Chapter에서 Data Scientist로 일하고 있는 Furiosa입니다.
지난 글 이후 오랜만에 이야기하고 싶은 주제가 있어 숨고 팀 블로그를 찾아오게 되었습니다. 다양한 분야의 사람들과 대화하다 보면, 여러 통계 용어를 듣게 됩니다. 모국어에 따라 영어 악센트가 다른 것처럼 같은 통계 단어 역시 자신의 분야에 따라 묘하게 뉘앙스가 다른 것이 저에겐 흥미로웠습니다. 때로는 이 단어가 통계 용어라고 인식하지 못하는 경우도 많았고, 서로 정의하는 개념이 달라서 미스 커뮤니케이션이 발생하는 경우도 있었던 것 같습니다.
이에 ‘알쓸데이, 알고 보면 쓸모 있는 데이터 이야기’라는 시리즈를 적어보려고 합니다. 제목에서 잘 드러나듯 특정 프로그램을 오마주 하였습니다. 이 시리즈에서는 통계 용어의 사용법과 그 이면의 통계 개념들을 알기 쉽게 소개해 보려고 합니다. 첫 번째 주제는 바로 데이터에 대한 이야기입니다.
데이터 vs 숫자
데이터라는 용어는 더 이상 통계 분야에 국한된 단어는 아닌 듯 합니다. 이미 일상에서 많이 접하는 단어이기 때문에 분야와 상황에 따라 그 의미를 다양하게 사용하고 있습니다. 하지만 단어의 사용법이 다양하다는 것은 잘못된 의사 결정을 야기하거나, 미스 커뮤니케이션을 유발할 우려가 있다는 의미이기도 합니다. 따라서 이번 글에선 현실 업무에서 미스 커뮤니케이션을 줄이기 위해, 데이터의 개념을 소개하고 이면의 통계적인 개념까지 이야기해 보려고 합니다.
아주 간단한 A/B 테스트 사례로 이야기를 시작해 보겠습니다.
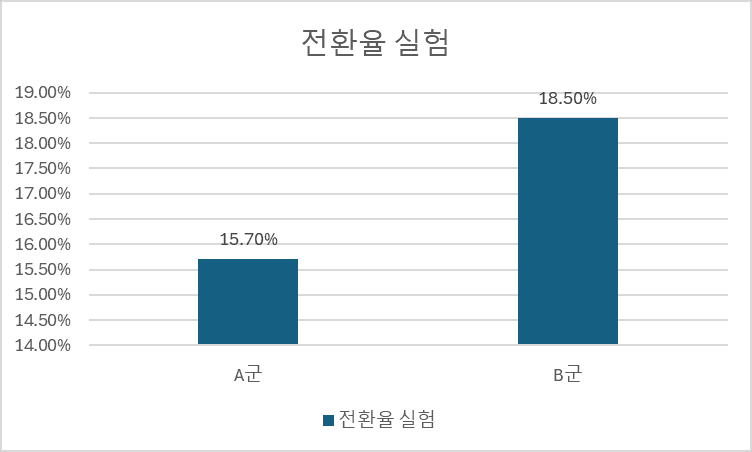
특정 화면의 변경된 UI에 대한 간단한 A/B 테스트를 진행하였습니다. A 군의 전환율이 약 15.7%, B 군의 전환율은 약 18.5%라고 집계되었습니다. 그렇다면, 우리의 의사 결정은 무엇인가요? B군 전환율이 더 높으니, B군으로 롤아웃 하는 것일까요? 실제로 현업에 있는 분께 이 질문을 한다면, ‘B군의 전환율이 더 높은지 통계적인 테스트를 하고 유의미하다면 B군으로 롤아웃하고 아니면 A군으로 롤백한다’ 라고 답변할 것 같습니다.
여기서 ‘이를 왜 테스트해야 하는가?’라는 생각을 해본 적 없으신가요? 통계에 입문하기 전, 저에게 이 질문은 너무 이상하였습니다. 15%보다 18%가 높은 건 숫자의 대소 비교만 할 줄 알면 너무 당연한 것이기 때문입니다. 이 의구심에 대한 대답이 오늘 이야기 주제인 ‘데이터와 숫자’ 입니다.
‘데이터’ 는 숫자로 표현되지만, ‘숫자’가 아닙니다. 이 이상한 문장을 잘 이해하기 위해서는 우선 두 개념이 차이가 있다는 것을 먼저 인지해야 합니다. 둘의 가장 큰 차이점은 데이터는 랜덤함을 가지고 있다는 점입니다. 즉, 지금의 실현화 된 결과는 15% vs 18% 이지만, 이는 확정된 숫자가 아닙니다. 15%라는 숫자도 변화할 수 있고, 18%라는 숫자도 변화할 수 있습니다.
“무슨 뚱딴지같은 소리지?”라는 생각이 들 수도 있습니다. 이에 대한 설명을 위해서 요새 유행하는 멀티버스라는 개념을 사용해 봅시다. 지금 우리가 사는 ‘Earth 1’에서는 이 실험의 결과 15% vs 18%가 나타났습니다. 동일한 환경의 'Earth 2'가 있다고 가정할 때, 동일한 테스트를 한다면, 같은 환경이라도 다른 숫자가 나타날 것입니다. 왜냐하면, 아무리 환경을 통제해도 우리가 통제할 수 없는 어떤 요소들이 존재하기 때문입니다. 예를 들어, 16% vs 17% 라고 합시다. 또 다른 지구 ‘Earth 3” 에서 동일한 테스트가 진행되고 또 다른 숫자를 얻게 됩니다. 18% vs 18% 라고 합시다. 이렇게 3가지의 멀티버스에서 진행된 테스트의 결과를 우리는 어떻게 해석해야 할까요? 여전히 B군이 더 높은 것 같은가요? 아니면 내 생각이 조금 약해졌나요?
이것이 궁극적으로 데이터를 다루는 직업이 존재하는 이유이기도 합니다. 저희가 보는 숫자는 확정된 숫자가 아닙니다. 똑같은 환경에서도 우연이 개입되기 때문에 다른 숫자가 나올 수 있습니다. 따라서 이러한 우연이 개입되었을 때도 여전히 특정 그룹의 숫자가 커야 하기에, A/B 테스트를 통해 이를 검증하는 작업이 필요합니다. 그리고 이것이 A/B 테스트의 통계적 추론입니다.
그렇다고 A군의 숫자와 B군의 숫자가 무한하게 실현되진 않습니다. 어떠한 범위를 가지게 되고 일정 확률로 숫자들이 실현됩니다. 이러한 규칙을 종합하여 우리는 분포라고 부릅니다. 따라서 분포를 안다는 것은 어떠한 숫자가 실현되는 규칙을 안다는 것이므로 분포에 대한 가정들이 통계적인 추론에서 아주 기본 베이스가 됩니다.
숫자로 표현되는 확률 변수에 대하여
약간 흐름을 바꿔서, 조금 더 심화 학습으로 들어가 봅시다.
앞서 데이터는 어떠한 것을 구현 또는 실현한 것이라는 표현을 썼습니다. 그럼, 무엇을 숫자로 표현한 것일까요? 이에 대한 설명을 위해서는 Random Variable (확률 변수) 이라는 개념을 이야기해야 합니다.
데이터를 조금 유식하게 표현하면 Random Variable이라고 표현할 수 있습니다. 서점이나 도서관에서 통계 입문서의 첫 장를 보면, 대부분 Random Variable 에 대한 설명으로 시작됩니다. 그리고 이 개념은 상당히 추상적이기 때문에 대부분 이 설명을 건너뛰거나 책을 덮었던 것 같습니다. 하지만, 이 개념은 통계의 전반에 아주 중요한 개념이기 때문에 어렵더라도 다시 한번 부딪혀보겠습니다.
Random Variable을 간단하게 설명하자면 X 와 Y를 연결한 것입니다. 보통 이를 ‘mapping’ 또는 ‘function’이라는 수학적인 개념으로 표현하기도 합니다. 이 개념이 상상하기 어렵다면, 아래와 같은 사랑의 작대기 형태라고 생각해 주세요.
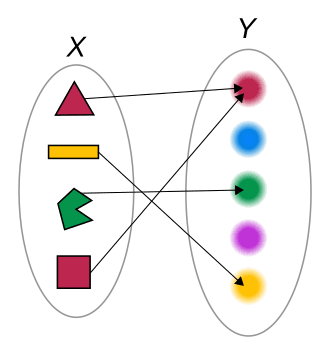
위의 그림에서 Y는 숫자의 세계이고, X는 이벤트의 세계입니다. 우리가 바라보는 데이터라는 것은 Y세계에 있는 '숫자' 들입니다. 하지만, 데이터는 엄밀하게 X를 Y에 맵핑한 것입니다. 즉, 우리가 보는 데이터는 X 세계에 있는 특정 '이벤트' 에 대응하는 Y 세계의 특정 '숫자' 를 보고 있는 것입니다.
앞서 설명한 예시로 설명해 보면, 우리가 본 A군 15% 전환율이라는 숫자와 B군 18% 전환율이라는 숫자는 어떠한 이벤트 1, 이벤트 2가 숫자로 실현된 결과입니다. 환경이 조금씩 달라지면, 앞서 멀티버스 설명처럼 다른 숫자가 나올 수 있습니다. 이는 다른 이벤트가 숫자로 실현된 것입니다. 이 논리에 근거하면, 결국 AB 테스트라는 숫자의 테스트는 궁극적으로 ‘A군에 발생할 수 있는 이벤트’와 'B군에서 발생할 수 있는 이벤트'를 비교하는 일이라고 해석할 수 있습니다.
설명이 직관적으로 와닿지 않더라도 오늘의 주제인 데이터와 숫자는 구분되는 개념이고, 그렇기에 우리는 AB 테스트와 같은 통계적인 추론 과정을 거쳐야 한다는 것만 가져가셔도 이 글의 목적은 충분히 달성되었다고 보입니다.
데이터 분석의 분산화
요즘 데이터 글을 읽다 보면, 데이터 민주화라는 표현을 많이 봅니다. 개인적으로 데이터 민주화라는 표현은 직관성이 떨어진다고 생각되기 때문에 ‘데이터 분석의 분산화’라는 표현을 쓰려고 합니다. 표현이야 어떻든, 이 개념은 아마 모든 데이터 조직에서 추구하는 이상향이 아닐까 싶습니다. 데이터가 구성원들에게 충분히 공급되어, 누구든지 데이터 분석을 할 수 있는 환경 그리고 데이터 분석가들에게는 더 심도 있는 분석을 할 수 있는 환경이기 때문에 데이터 직군 종사자라면 누구나 이러한 상황에서 일하기를 희망합니다.
데이터 분석의 분산화 라는 가치를 달성하기 위해서 전사 차원에서의 데이터 문해력이 아주 중요한 전제 조건입니다. 그리고 이를 위해서 더 정확한 용어를 사용하고자 하는 노력이 필요합니다. 이러한 맥락에서 이 시리즈를 지켜봐 주시면 감사하겠습니다.
앞에 있는 내용들은 이해하기 쉽도록 간단히 설명하였기 때문에 엄밀함을 버리고 많은 개념을 단순화 측면이 있습니다. 개인적으로 소망하는 이 글의 목적은 독자 분들께 통계학 서적을 열어 볼 호기심과 용기를 드리는 것입니다. 제 글을 통해 더 궁금하신 점이 있으시다면, 꼭 통계 책을 다시 한번 읽어보시길 권유해 드립니다.
긴 글 읽어주셔서 감사합니다. 다음 시리즈로 또 찾아오겠습니다.
- #data
- #data-driven
- #data-driven organization
- #start up
- #data-driven decision making
- #statistics



