
데이터 분석가가 일하기 좋은 조직 만들기 : 숨고에서의 사례를 통해
안녕하세요.
저는 숨고에서 Product Data Analyst로 일하고 있는 Nova라고 합니다. 시중에는 데이터와 관련된 수많은 글들이 존재하는데 대체로 분석가가 개인으로서 성장할 수 있는 방법에 대한 내용이 많습니다. 반면 팀이나 회사 차원에서 어떻게 하면 데이터 분석가로 이루어진 조직이 더 좋은 성과를 낼 수 있는가에 대한 이야기는 많지 않습니다.
그러한 갈증을 해소하기 위해 이번 글에서는 숨고의 Data Chapter의 실패 사례와 이에 대한 개선안을 통해 데이터 분석가로 이루어진 팀이 효율적으로 분석을 수행하기 위해서는 무엇이 필요한가에 대해 이야기해보겠습니다.
회사의 성장 단계와 분석팀의 역할
많은 경우 회사가 처한 상황에 따라 구성원에게 요구되는 역할은 달라집니다. 이는 숨고도 다르지 않았는데요.
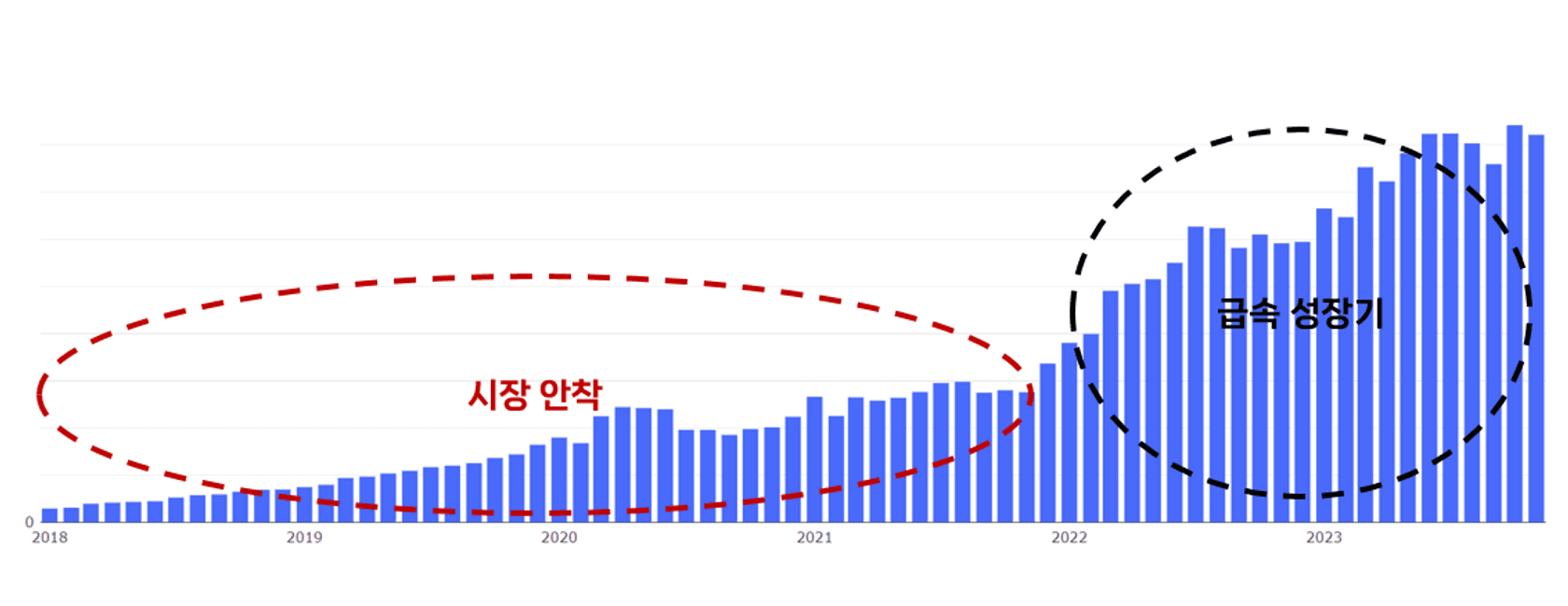
위 이미지는 숨고의 매출 성장 추세를 나타낸 차트입니다. 2021년까지는 매출이 서서히 상승하다가 2022년 중순부터 2021년 매출의 2배 가량을 돌파하고 이후로 지속적으로 성장하는 것을 확인할 수 있습니다.
시장 안착기에 숨고의 Data Analyst들에게 요구되던 역할은 주어진 일을 빠르게 처리하는 것이었습니다. 이 시기는 숨고에 있어 생존이 가장 우선시되던 시기로 장기적인 관점에서 프로세스를 수립하는 것보다는 매일매일 당면하는 비즈니스적인 위협들을 발빠르게 해결하는 것이 분석가들의 지상과제였습니다. 자연스럽게 당시 분석가들의 역량도 비즈니스 이슈에 빠르게 대응할 수 있는 방향으로 개발되었고 챕터의 방향성도 장기적인 성장보다는 문제를 빠르게 해결하는 것에 초점이 맞춰져 있었습니다.
저는 숨고가 시장 안착기에서 급속 성장기로 전환되는 시기에 입사했습니다. 이 당시 제가 바라본 숨고는 많은 변화를 겪었는데요. Data Chapter에서 제가 체감한 가장 큰 변화는 분석가와 분석을 요청하는 사람들의 데이터 분석에 대해 가지는 태도의 변화였습니다.
요청자들은 자신들에게 영감을 줄 수 있는 분석 결과를 더욱 원하기 시작했습니다. 분석가 또한 요청 받은 것을 해결하는 것을 넘어서 장기적인 관점에서 분석을 하기 위한 방법을 고민하기 시작했습니다.
이러한 요청자와 분석가 모두의 니즈를 충족시키기 위해서 효과적인 데이터 분석을 위한 기반이 필요했습니다.
효과적인 데이터 분석을 위한 기반
효과적인 데이터 분석을 위한 기반은 크게 세 가지 요소로 구분할 수 있습니다.
지식의 접근성 : 문서화
지식의 접근성이 보장된다는 것은 데이터 분석의 결과들이 잘 축적되어 있어 분석가와 회사의 구성원들이 간편하게 분석 문서에 접근해 Insight를 얻을 수 있는 것을 말합니다. 이는 회사의 모든 구성원들에게 큰 이점을 제공합니다. 분석가는 같은 분석을 반복해서 진행할 필요가 없으며 축적된 지식을 기반으로 새로운 분석을 설계할 수 있습니다. 다른 구성원들도 기존 분석 결과를 자신의 업무 설계에 신속하게 활용할 수 있습니다.
효과적인 분석 방법론 : 업무 프로세스 정리
이는 회사의 구성원들이 손쉽게 활용할 수 있는 일련의 분석 프로세스가 존재하는지를 지칭합니다. 예를 들면, 분석을 요청하는 양식부터 시작해서 A/B테스트에 대한 각 직군의 R&R 정리까지 데이터 분석과 연관된 업무에 있어서 효과적인 결과물을 담보하는 일련의 프로세스가 있다면 좋은 업무 프로세스를 가진 분석팀이라고 이야기할 수 있습니다. 이러한 기반이 갖춰져 있다면 개개인이 뛰어난 Data-driven 역량을 가지고 있지 않더라도 데이터 분석을 활용해 효과적으로 업무를 진행할 수 있습니다.
빠르고 가독성이 높은 데이터 수급 : Data Pipeline 개선
제가 이야기하고 싶은 데이터 수급에는 크게 두 가지가 있습니다. 하나는 데이터 마트 작업을 통한 분석 속도 및 정확성의 개선입니다. 데이터가 안정적이고 분석에 용이한 형태로 적재되면 분석가가 데이터 정제 과정에서 소모하는 시간을 크게 단축할 수 있습니다. 다른 하나는 지표 변동에 대한 alert입니다. 회사의 주요 지표에서 변화가 감지된다면, 이에 대한 초동 대처를 분석가가 하는 경우가 많습니다. 그런데 지표는 그 자체로 어느 정도의 변동성을 가지고 있는 경우가 많습니다. 이러한 자연스러운 흔들림이 아니라, 실질적인 지표의 변화가 발생했을 때, 이를 정확히 감지해 분석가에게 인지시켜 준다면 false alarm으로 인해 발생하는 리소스 낭비를 방지할 수 있습니다.
위에서 언급한 세 가지 기반을 마련하기 위해 지난 2년 간 Data Chapter는 다양한 시도를 했습니다. 그 중 가장 중요한 것들을 하나씩 간략하게 소개드리도록 하겠습니다.
문서화
문서화의 필요성을 느꼈던 이유에는 크게 두 가지가 있었습니다. 인원의 입사, 퇴사 과정에서 과거 기록이 유실된다는 점과 분석 결과들이 축적되지 않고 휘발된다는 점이었습니다. 과거 지식의 유실은 상대적으로 대처가 쉬웠습니다. 프로덕트의 변화와 이슈, 기본 정보 등을 기록하는 문서를 만들고 이를 관리하는 것만으로 손쉽게 대처가 가능했습니다.
반면 분석의 자산화에는 훨씬 큰 허들이 존재했습니다. 분석의 자산화를 위해 한 첫번째 주요 시도는 Notion을 활용한 Insight Wiki입니다
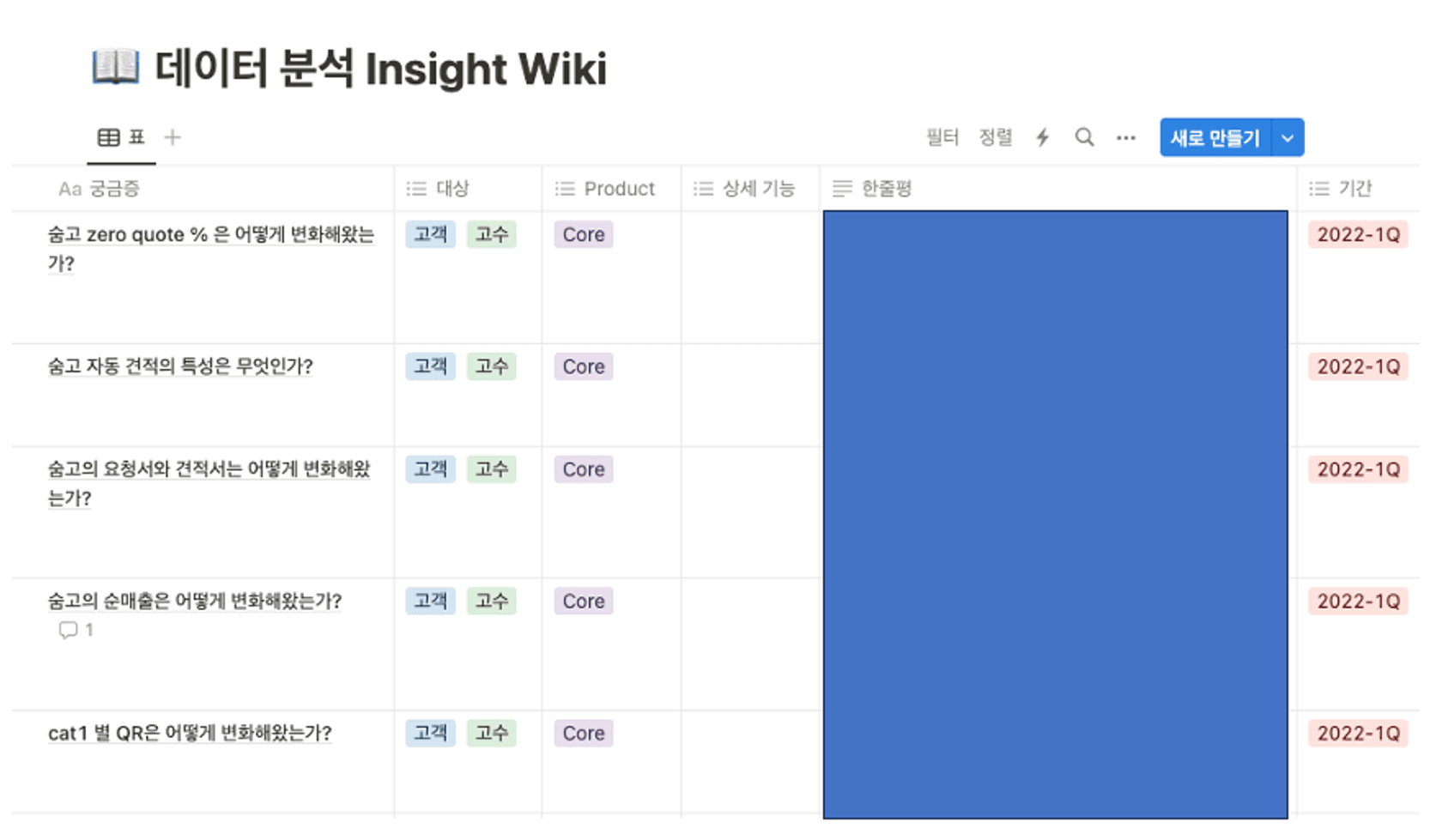

Insight Wiki는 데이터 분석 결과를 정리한 Insight Wiki와 A/B테스트 결과를 작성해둔 A/B 테스트 Insight Wiki 두 가지로 나누어 운영했으며 데이터 분석 결과와 실험이 주는 Insight를 간편하게 알 수 있도록 구성했습니다. 또한 탐색 편의성을 위해 분석과 실험 결과에 대한 구별법(예를 들면 분석의 대상이 고객이었는지 고수였는지, 해당 실험을 담당한 스쿼드가 어디였는지 등)을 기재해둔 것이 가장 큰 특징이었습니다.
하지만 결과적으로 Insight Wiki는 숨고팀 멤버들의 지지를 받지 못하고 자리 잡는 것에 실패했습니다.
그 이유를 분석해보자면 첫번째로는 숨고팀 멤버들의 User flow를 이해하지 못한 점이었습니다. 현재 숨고팀의 대부분의 문서는 Atlassian의 Confluence에 있습니다. 따라서 대부분의 숨고팀 멤버들은 업무를 위해 Confluence를 탐색하는데 이 탐색 범위에서 Notion은 자연스럽게 제외가 되었던 것이지요.
두 번째는 작성자의 작성 난이도가 높았다는 점이었습니다. 작성자가 편하게 작성할 수 있도록 마련해둔 한줄평인 lessons learned가 좁은 공간에 실험, 분석 결과를 요약해서 작성하는 것을 강제했고 이것이 되레 작성자에게 부담으로 작용했습니다.
이렇게 Insight Wiki에서 얻은 교훈을 바탕으로 저희는 데이터 분석 결과를 제대로 축적할 수 있는 숨고 데이터 인사이트를 런칭했습니다.
숨고 데이터 인사이트의 주요 특징은 다음과 같습니다.
- Confluence에 위치해 숨고팀 멤버들의 검색에 노출된다
- 문서의 구분이 숨고의 customer experience journey와 대응되어 내가 찾고 싶은 주제를 손쉽게 찾을 수 있다
- 예를 들면 가입은 초반부에 위치하고 리텐션 관련된 내용은 후반부에 위치함
- 문서의 서두에 분석 결과에 대한 요약을 추가해 내용을 손쉽게 파악할 수 있다
- 문서 작성 가이드를 활용해 간단하게 문서 작성이 가능하다
이렇게 구성을 변경하니 문서 작성과 조회 모두 활발해졌고 분석의 자산화가 문화로서 정착할 수 있었습니다.
업무 프로세스 정리
저희가 업무 프로세스 정리 관련된 시도를 하게 된 원인은 분석가가 수행한 분석들이 효율적이지 못하거나 스스로도 효능감을 느끼지 못하는 경우가 많았기 때문입니다. 저의 입사 초기를 돌이켜보면 분석 요청자에 비해 분석가가 매우 부족했었습니다. 그래서 분석가는 빠르게 데이터를 뽑아주는 것에 치중할 수 밖에 없었고, 자연스럽게 내가 뽑는 데이터가 무엇을 위한 것인지 알기 어려울 뿐더러 현실을 잘 반영해 데이터 분석을 설계하기 어려웠습니다.
이러한 특징이 가장 극명하게 나타난 것이 A/B 테스트에 대한 분석입니다. 만약 Optimizely와 같은 A/B 테스트 툴이 있거나, 적절한 개발 역량 및 Amplitude와 같은 성과 측정 툴이 있다면 분석가 없이 실험을 진행하는 것이 가능합니다. 분석가가 매우 부족한 시기에 숨고의 Product Owner와 스쿼드는 분석가 없이 이런 다양한 툴을 사용해 실험을 진행하는 업무 방식에 익숙해졌고 대부분의 분석을 스스로 진행한 후 해결되지 않는 경우에만 분석가에게 요청을 하곤 했습니다.
이러한 요청은 대체로 분석의 시각이 굉장히 고착화된 경우가 다수를 차지합니다. Product Owner가 데이터 분석 과정에서 목표 수립, 가설 설정과 같은 초기 단계를 스스로 완성해둔 경우가 많기 때문입니다. 배경지식이 많지 않은 분석가 입장에서는 요청한 그대로 데이터를 뽑는 것 이상을 하기 어려운 경우가 자주 발생했습니다.
이러한 문제를 해결하기 위해 다양한 시도를 했는데, 그 중 대표적인 것이 A/B 테스트 실행 프로세스 설계입니다. 여러 참고 문헌들을 활용해 (TDS 자료, HBR 자료 등) 아래와 같이 설계를 진행하고 완성된 프로세스를 활용해 실험을 설계해보려 했습니다.

위와 같은 프로세스를 만들어 A/B 테스트를 시도해 보았지만 Product Owner와 분석가 모두에게 외면받는 안타까운 결과만 남았습니다.
이에 대한 원인으로는 먼저 Product Owner에 대한 배려가 부족했다는 점입니다. 제가 설계한 A/B 테스트 프로세스는 꽤 복잡할 뿐만 아니라 기존에 Product Owner가 일하던 방식과 굉장히 다른 방식으로 일해야 했습니다. 익히기도 어렵고 일하는 방식도 크게 바꿔야하는 일을 하지 않는 것은 어떻게 보면 무척 자연스러운 일이었습니다.
두번째는 A/B 테스트에 대한 지식 부족입니다. 이 프로세스를 진행할 당시에 저는 순전히 desk research를 통해 프로세스를 수립했고, A/B 테스트를 진행하면 나타날 수 있는 여러 상황에 대한 지식과 통계에 대한 전문성이 부족한 상태였습니다. 따라서 이해관계자들에게 A/B 테스트에 분석가가 더 개입해야할 당위성을 설명하기도 어려웠고 A/B 테스트의 설계와 해석에 있어서도 분석 전문가로서 의견을 피력하는 것에 큰 어려움을 느꼈습니다. 이런 상황에서 프로세스만 제시하고 이를 따르기를 바라는 것은 마치 아이가 떼를 쓰는 것과 같은 느낌이었을 것입니다.
이러한 문제점을 극복하고 분석가의 A/B 테스트 관여도를 높히기 위해 저희가 수립하고 있는 새로운 업무 프로세스는 다음과 같습니다. 첫째는 분석가들이 A/B테스트에 대한 지식을 쌓는 것입니다. 시중에는 A/B 테스트에 대한 노하우를 소개하는 서적이 있는데 챕터 내에서 스터디를 하며 관련 지식을 충분히 습득해나가고 있습니다. 이렇게 스터디에서 얻은 지식들로 숨고에서 A/B 테스트를 하며 유의해야 하는 사항을 정리하고 분석가들의 실험 설계 및 분석에 대한 스탠스를 확정할 계획을 갖고 있습니다. 예를 들면 이론적으로 실험에서 나타날 수 있는 문제들을 정리하고 이와 같은 사례들이 숨고에서 어떻게 발현될 수 있을지를 인지하며, 이에 대한 대처법을 챕터 차원에서 정리해두고 A/B 테스트 설계 시 이 의견을 반영해 진행하는 방식을 계획하고 있습니다.
두 번째로는 Product Owner의 업무 프로세스에 분석가가 단계적으로 녹아드는 것입니다. A/B테스트와 관련된 업무 방법을 급격히 바꾼다면 Product Owner와 분석가 모두 쉽게 적응하기 어렵습니다. 따라서 단계적으로 변화를 가져가 이해관계자들이 변경된 프로세스에 점진적으로 적응해나갈 수 있도록 진행할 계획입니다. 이러한 접근법은 이해관계자들이 프로세스의 이점을 체감해 새로운 시도를 하고, 이러한 시도에서 다시 유용함을 느끼는 선순환을 발생시킬 수 있어 큰 변화도 쉽게 정착시킬 수 있는 장점이 있습니다. 이러한 과정을 거쳐 최종적으로는 보다 더 안정적이고 효율적인 업무 프로세스를 수립할 계획입니다.
Data Pipeline
데이터 파이프라인 개선을 위해서도 다양한 시도를 했는데, 그 중 이번에 소개드릴 것은 그 중 지표 변동에 대한 alert을 개선하는 프로젝트입니다.
기존에 숨고에서는 일별, 시간별 지표의 등락을 확인해서 원인을 분석하곤 했습니다. 예를 들면 이번 주 월요일의 매출이 지난 주에 비해 30% 하락한 것을 누군가 감지하면 분석가는 혹시 버그가 있지는 않았는지, 지난 주의 지표값이 매우 컸던 것이 아닌지 등의 여러 가능성을 모두 확인해서 원인을 찾아야 했습니다. 이런 일을 반복적으로 하는 것은 분석가 개인의 동기부여 및 효능감에 악영향을 미쳤고 정말로 문제가 있는지를 파악하는 것에 오랜 시간이 소요되어 회사 차원에서 기민한 대응을 하기에도 어려웠습니다.
이러한 상황을 개선하기 위해 여러 시도를 했는데 첫 번째로 시도한 것은 Slack을 통한 지표 공유 방식 개선입니다. 숨고에는 예전부터 시간별, 일별 데이터를 Slack에 발송하는 기능이 존재했습니다. 여기에 포함된 지표가 매우 많고 어떤 지표가 문제인지 확인하기가 어려워 지표를 줄이고 문제가 되는 지표를 highlight하는 기능을 추가했습니다. 다만 이 방식도 아주 성공적이지 못했는데 주된 원인으로는
- 지난 주 데이터에 기반해 지표를 highlight하는 구조해서 지난 주의 데이터가 특이한 경우 false alarm이 발생한다는 점
- 지표의 이상을 확인하기 위해선 채널을 지속적으로 확인해야한다는 점
- 지표의 숫자를 줄이지 못했다는 점
위 세 가지 문제점을 지니고 있었습니다.
두 번째로는 Redash를 사용해 지표별 모니터링 대시보드를 구성했습니다. 이 대시보드의 가장 큰 특징은 일별 대시보드는 최근 7일, 주별 대시보드는 최근 3주 데이터를 활용해 문제가 되는 날짜를 표시해주는 방식이었습니다. 문제가 되는 날짜를 지칭한다는 점에서는 개선되었지만, 여전히 지표의 이상을 탐지하기 위해선 이 대시보드를 지속적으로 조회해야한다는 문제점을 가지고 있었습니다.
이러한 문제점들을 개선하기 위해 최근 자동화 alarm 체계를 구성했습니다. 우선 Slack을 활용해, 최근 1년 간 지표 분포에서 outlier가 되는 임계점을 지표 분포에서 약 1%에서 3%정도 밖으로 벗어나는 값으로 정했습니다. 그리고 이렇게 정한 임계점에서 outlier가 되는 경우 Slack을 통해 알람을 발송하고 이 지표의 추세를 활용할 수 있는 Amplitude 대시보드와 Redash 대시보드를 제공하는 방식입니다. Amplitude 대시보드와 Redash 대시보드에서는 지표의 추세뿐만 아니라 관련 지표의 추세 또한 확인해 모니터링 지표의 변동이 어디에서 기인한 것인지 확인할 수 있도록 했습니다.
위와 같은 개선은 분석가가 지표를 항시 모니터링할 필요 없이, 리소스를 쏟아야할 시기를 명확히 지칭해주고, 지표에 문제가 생긴 것을 전사적으로 상대적으로 정확하게 공지할 수 있어 이전보다 효율을 높일 수 있었습니다.
맺음말
도스토예프스키는 인간을 적응하는 동물이라고 말했습니다.
저는 이 말이 사람을 둘러싼 환경이 스스로가 어떤 일을 할 것인지에 큰 영향을 미친다는 것이라고 생각합니다. 회사의 성장을 위해선 구성원 개개인의 성장이 필요한데 이에 크게 영향을 줄 수 있는 것이 구성원이 속한 조직의 성장과 문화입니다. 분석가가 빠르게 성장하고 회사의 성과에 더 큰 기여를 하기 위해선 분석 자료들이 잘 문서화되어 있고, 적절한 분석 프로세스를 가지고 있으며, 막힘없는 Data Pipeline을 가지고 있는 것이 중요하다고 생각합니다.
제 글이 데이터 분야에 관심있는 많은 분들께 영감을 주었기를 고대합니다. 추후 글에서는 이번 글에서 축약해서 전달드린 내용을 더욱 자세하게 공유하고, 아예 소개되지 않은 것들에 대해서도 작성해볼 예정입니다. 많은 기대 부탁드려요!
긴 글 읽어주셔서 감사합니다.
- #ab test
- #data
- #data documentation



