
카프카 커넥트 효율적으로 관리하기
안녕하세요! 숨고 데이터 엔지니어 Daisy입니다.
데이터웨어하우스를 위한 스트리밍 데이터 파이프라인을 관리하면서 어려웠던 점과 개선한 부분에 대해 공유하고자 합니다. 숨고에서는 어떻게 카프카를 사용하고 있고, 왜 새로운 관리 프로세스가 필요했는가, 그리고 관리 프로세스 개선을 위해 어떤 작업을 진행했고 실제로 어떤점이 개선되었는가에 대해서 소개하겠습니다.
들어가며
숨고 시스템의 MSA화가 진행되면서 카프카 플랫폼(스트리밍 데이터 파이프라인을 위한) 운영을 하는데 더욱 효율적인 관리가 필요해지기 시작했습니다. 데이터베이스의 수가 늘어날때마다 DW와의 동기화를 위해 매번 새로운 소스 커넥터와 싱크 커넥터를 새롭게 정의하고 생성하는 작업을 진행해야 했고, 또한 예기치 못한 장애가 발생, 그리고 그 장애를 인지하지 못하면 모든 데이터를 처음부터 다시 동기화해야 하는 경우도 발생했습니다.
따라서 숨고에서는 스트리밍 데이터 파이프라인의 성숙도 향상을 위해 방법을 모색하기로 했습니다. 카프카 커넥트의 관리의 편의성을 높일 수 있는 프로세스를 구축하고, 안정화를 위한 모니터링을 강화하기 위해 Bitbucket 파이프라인 적용과 쿠버네티스의 라이브니스 프로브(Liveness Probe) 적용 등 구체적인 방법을 고민하기 시작했습니다.
숨고에서 카프카를 사용하는 방법
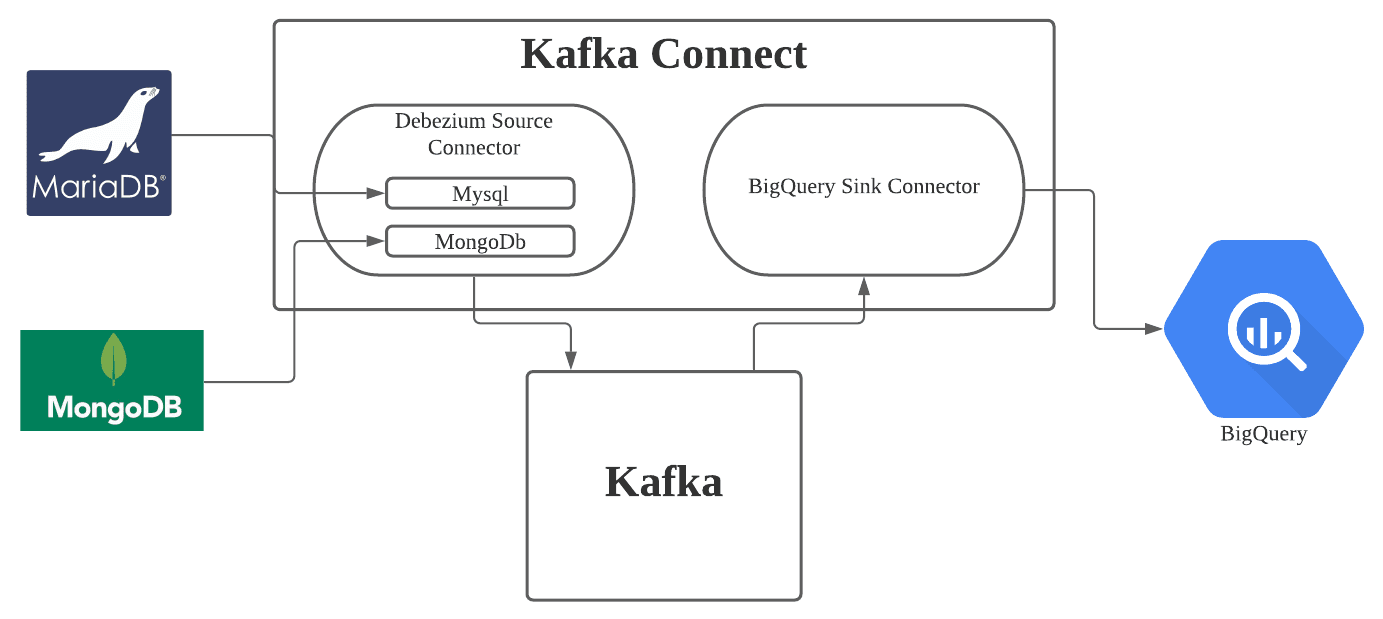
숨고에서는 프로덕션 DB에서 빅쿼리 데이터 웨어하우스로 데이터를 동기화하는데 카프카를 사용하고 있습니다. 카프카 커넥트를 사용해서 파이프라인을 만들고 있으며, 프로덕션 DB인 MariaDB에서 CDC를 이용해 데이터를 가져오기 위해서 디비지움의 커넥터 플러그인을 사용하고 있습니다.
카프카 커넥트를 도입하게 된 이유
숨고에서는 Data-Driven 기반의 효율적인 의사결정을 하기 위해 Bigquery에 데이터웨어하우스를 구축했습니다. 처음에는 Apache Airflow 워크플로우 도구를 사용해 배치 단위의 데이터 동기화로 충분했습니다.
하지만 점차 서비스 이용자 수가 늘어나면서 데이터 양이 증가하기 시작했고, 한 테이블에서만 하루 약 2천만개 이상의 트랜잭션에 대한 변경 사항도 추적해야했습니다. 트랜잭션의 증가로 기존의 배치 처리로 동기화하는 방식에서 벗어나야 했습니다.
- 배치 단위로 데이터를 동기화하기까지 걸리는 소요시간이 점차 길어짐
- 새로 추가(INSERT)된 데이터뿐만 아니라 기존의 데이터가 갱신(UPDATE) 된 경우도 포함해서 동기화가 이루어져야 하기 때문에, 한번에 너무 많은 양의 데이터 동기화가 요구됨
- 배치 단위의 동기화를 최소한으로 짧게 가져가도, 실시간 데이터 분석을 진행하기에는 어려움
위와 같은 이유에서 변경되는 데이터에 대한 실시간 동기화를 위해 이벤트 기반 데이터 처리를 고려하게 되었고, 숨고에서는 Apache kafka 시스템의 kafka connect를 사용해서 데이터 동기화를 진행하게 되었습니다.
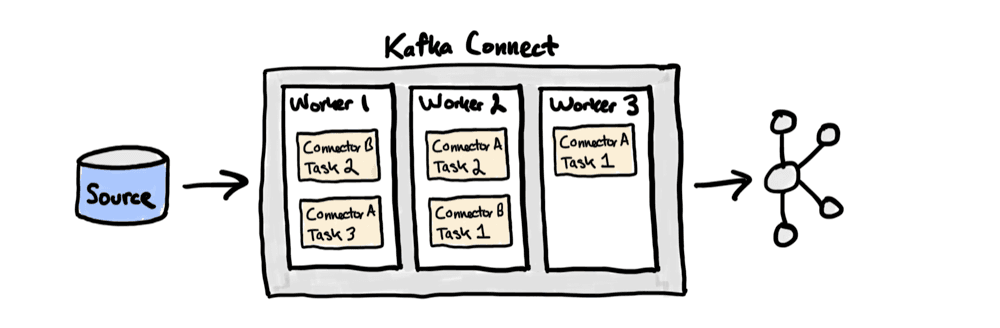
카프카 커넥트란? Kafka Connect는 Apache Kafka 관련 생태계의 오픈 소스 중 하나로, 카프카와 다른 외부시스템 간에 데이터를 복제하고 이동시키는데 사용할 수 있습니다. Kafka Connect는 커넥터 플러그인을 작업 프로세스(Worker process)에 설치한 후 REST API를 호출해서 특정 커넥터를 구성하고 실행할 수 있으며, 이때 Connector는 데이터를 복사할 위치를 정의하고, Connector Instance는 카프카와 다른 시스템 간의 데이터 복제를 관리하는 역할을 합니다.
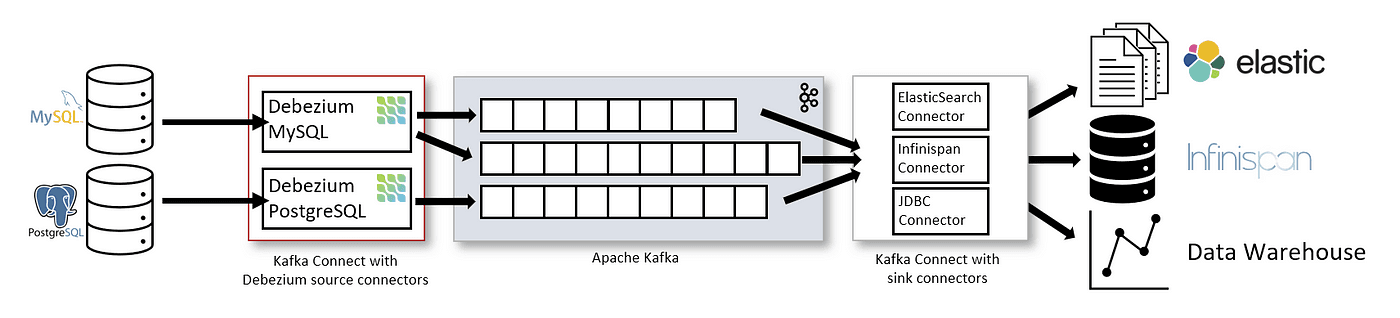
디비지움(Debezium) 커넥터란? Debezium 커넥터는 Kafka Connect 기반의 플러그인의 하나로, Debezium의 CDC 기술을 사용해서 데이터베이스의 변화를 모니터링하고 변화된 데이터를 카프카에 전달할 수 있도록 합니다. Debezium이란 소스 데이터베이스에 대한 변경 사항을 캡처하고 데이터베이스 시스템을 모니터링할 수 있는 분산 오픈 소스 CDC 플랫폼입니다. 아래의 그림은 Debezium을 기반으로 하는 변경 데이터 캡처 파이프라인 아키텍처입니다.
"카프카 커넥트"의 "커넥터" 관리 프로세스 구축
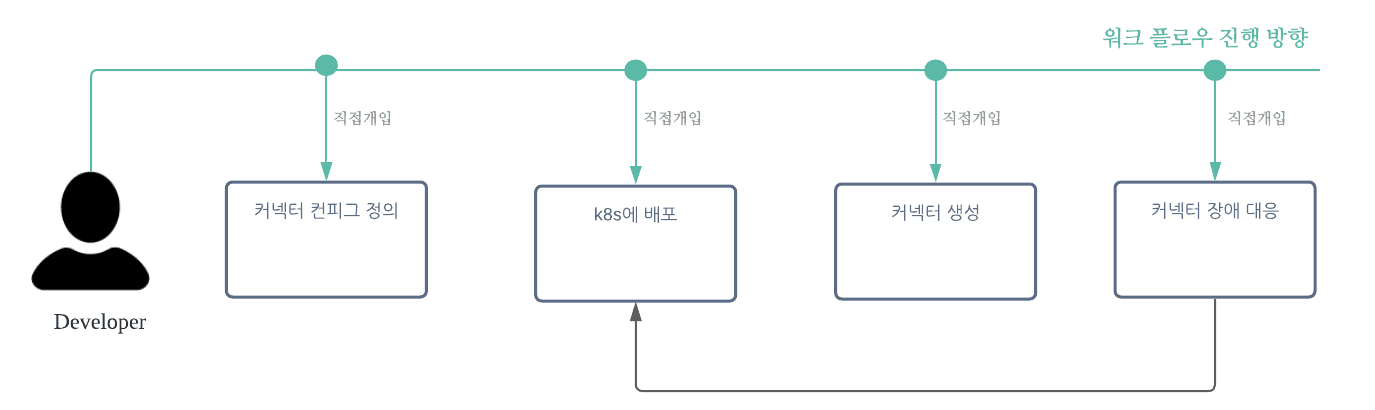
데이터 복제를 위해서는 커넥터를 생성해 주어야 합니다. 다시 말해 커넥터 구성을 위한 설정 값들을 넣어 POST 요청을 보내서 커넥터를 생성할 수 있습니다. 하지만 이러한 여러개의 커넥터들을 추가/유지/보수하기 위해서는 일련의 작업들이 필요했고, 일련의 작업들 중에 개선시킬 수 있는 단계를 선별해서 새로운 프로세스를 구성하기로 했습니다.
선별한 문제점들을 아래와 같이 정리해 볼 수 있습니다.
(1) 커넥터 컨피그 관리의 어려움
커넥터의 구성(Connector Configuration)을 위한 설정을 정리한 컨피그(Configuration file)가 필요했습니다. 프로세스 개선 전에는 아래 코드와 같이 curl 리눅스 명령어와 커넥터 구성을 위한 설정 값이 함께 관리되고 있었습니다. 체계적이지 않았으며 커넥터의 구성 값을 재사용하기 어려웠습니다.
kubectl exec -ti $POD_NAME -- curl -X POST \ http://$POD_IP:8083/connectors/ \ -H 'Cache-Control: no-cache' \ -H 'Content-Type: application/json' \ -d '{ "name": "source-connector-1", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "db1.host.com", "database.port": "3306", ... } }' kubectl exec -ti $POD_NAME -- curl -X POST \ -H "Accept:application/json" -H "Content-Type:application/json" http://$POD_IP:8083/connectors/ \ -d '{ "name": "sink-connector-1", "config": { "connector.class": "com.wepay.kafka.connect.bigquery.BigQuerySinkConnector", "tasks.max" : "1", "topics" : "table1", ... } }'
(2) 커넥터 추가/유지/보수를 위해 계속되는 반복적인 작업
아래에 명시되어 있는 모든 단계(Step)에서 엔지니어의 직접적인 개입이 필요했으며, 새로운 커넥터를 생성해야 할 때마다 모든 작업을 반복해야 했습니다.
- 카프카 커넥트 파드가 생성된 후, 커넥터 생성 (위의 모든 커넥터 구성 요소를 담은 컨피그 파일을 bash 쉘 스크립트로 만들어 실행)
- 커넥터 장애 발생 시에도, 커넥터를 Restart 하거나 재생성이 필요
(3) 예기치 못한 장애, 생성된 커넥터가 사라지는 경우 모니터링이 되지 않음
- 커넥트 파드에 예기치 못한 에러가 발생한 경우, 에러에 대해 인지할 수 있는 모니터링의 어려움
- 장애의 인지가 늦어진 경우, 더 큰 피해로 이어질 수 있기 때문에 빠른 조치가 요구됨
개선 방향을 정하자
저희는 직접 개입해서 실행해야 하는 부분을 최소화하고, 예기치 못한 장애가 발생했을 때는 장애 파악과 더불어 빠른 조치가 이루어질 수 있도록 하는 것을 목표로 잡았습니다.
다음은 개발을 시작하기 전에 구상한 개선 방향과 수행해야 할 작업들을 리스트업 했습니다.
현재 숨고에서는 카프카를 쿠버네티스 환경에서 운영중입니다. 따라서 쿠버네티스에서 제공하는 기능을 이용해서 워크플로우를 개선하기로 했습니다.
- 커넥터 구성을 위한 설정 값과 커넥터를 생성할 때 사용되는 리눅스 명령어의 분리
- k8s에 배포 후, 커넥터가 자동으로 생성 될 수 있도록 함
- 커넥트 파드가 예기치 못한 에러로 인해 정상으로 작동되지 않는 경우 상황 인지 필요(health check)
- 커넥트 파드가 정상동작하지 않을 시에는 알림을 주고 스스로 장애 대응 작업 진행(self-healing)
어떤식으로 작업했을까
작업은 크게 두 가지로 커넥트 파드 내부에서 돌아갈 수 있는 코드를 작성하고 쿠버네티스 기능을 적용하는 것이었습니다. 최종 폴더 구성은 아래와 같습니다.
.
├── cache.txt
├── config
│ ├── sink.yaml
│ └── source.yaml
├── k8s_manifest
│
├── connect.yaml
│ ├── kafka.yaml
│ ├── schema-registry.yaml
│ └── zookeeper.yaml
├── manage.py
└── requirements.txt
yaml 형식으로 컨피그 구성 및 자동으로 커넥터를 등록할 수 있는 프로세스 만들기
(1) python을 사용할 수 있도록 Debizium 커넥트 이미지 재구성 하기
워크플로우를 개선하기 위해 python을 사용하기로 했습니다. 따라서 connect 도커 이미지에 python을 사용할 수 있는 환경을 추가해 Base 도커 이미지를 만들었습니다.
FROM debezium/connect:1.4 USER root RUN set -ex \ && ln -s -f /usr/share/zoneinfo/Asia/Seoul /etc/localtime RUN set -ex \ && yum -y update \ && yum -y groupinstall "Development Tools" \ && yum -y install openssl-devel bzip2-devel libffi-devel WORKDIR /app COPY ./Python-3.8.3.tgz . RUN set -ex \ && tar xvzf ./Python-3.8.3.tgz \ && cd Python-3.8.3 \ && ./configure --enable-optimizations \ && make altinstall \ && cp /usr/local/bin/python3.8 /usr/bin/python
bigquery sink connector 플러그인 등 새로운 등록이 필요한 커넥터 플러그인은 도커 이미지 만들때 추가해서 구성
(2) 커넥터 구성을 위한 설정 값을 관리하기 위해 yaml 형식으로 재구성
curl 리눅스 명령어와 분리해서 커넥터 설정을 관리하기 위해 컨피그 파일을 yaml 파일 형식으로 관리할 수 있도록 구성했습니다.
- 공통되는 설정은 따로 정의
- resource에 각 소스 커넥터와 싱크 커넥터 설정 정의
resource: - name: source-connector-1 config: database.hostname: db1.host.com database.port: '3306' database.user: user database.password: password database.server.name: db1 database.include.list: db1 database.server.id: 1
resource: - name: bigquery-table1 config: topics: table1 datasets: .*=kafka - name: bigquery-table2 config: topics: table2 datasets: .*=kafka
(3) python으로 커넥터 생성을 자동화
커넥터 관리 프로세스를 구축하기 위해 가장 중요한 작업이라고 할 수 있습니다. python으로 커넥터 설정을 담고 있는 컨피그 파일을 읽어 POST 요청을 보내 커넥터를 생성할 수 있도록 합니다.
- 쿠버네티스 환경에서 돌아갈 수 있도록 구성
- config 폴더에 정의되어 있는 sink.yaml과 source.yaml을 설정값을 사용해 커넥터 구성 및 생성
BASE_SINK_CONFIG = { "connector.class": "com.wepay.kafka.connect.bigquery.BigQuerySinkConnector", "tasks.max": "1", ... } BASE_SOURCE_CONFIG = { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", ... } class Connector: def __init__(self, filename=None, config=None): self.url = f'http://{socket.gethostbyname(socket.gethostname())}:8083/connectors/' self.filename = filename self.config = config def get_resources(self): with open(os.path.join(BASE_DIR, 'config', self.filename)) as f: r = yaml.load(f, Loader=yaml.FullLoader) return r def execute(self): resources = self.get_resources() for resource in resources['resource']: name = resource['name'] config = copy.deepcopy(self.config) config.update(resource['config']) r = requests.post(self.url, json={'name': name, 'config': config}) print(r.status_code) @cli.command() def initial(): Connector(filename='sink.yaml', config=BASE_SINK_CONFIG).execute() Connector(filename='source.yaml', config=BASE_SOURCE_CONFIG).execute()
커넥트 파드 매니페스트 구성 하기
커넥트 파드가 제대로 동작한 후에 커넥터를 생성할 수 있습니다. 따라서 파드가 생성된 직후 python 스크립트가 실행될 수 있도록 쿠버네티스 컨테이너 라이프사이클을 사용해 매니페스트를 구성했습니다.
(1) 쿠버네티스 환경에서 사용할 수 있도록 도커 이미지 구성
위에서도 언급했듯이 카프카를 쿠버네티스 환경에서 운영하고 있습니다. 따라서 쿠버네티스의 컨테이너 라이프 사이클과 함께 파드 내부에서 돌아갈 수 있도록 위에서 만든 BASE 도커 이미지에 config, manifest, manage.py에 추가해서 최종 도커 이미지를 만들었습니다.
FROM base-connect-python:latest RUN set -ex \ && ln -s -f /usr/share/zoneinfo/Asia/Seoul /etc/localtime COPY . /app RUN set -ex \ && chmod -R 755 /app \ && pip3.8 install -r /app/requirements.txt
(2) 쿠버네티스 컨테이너 라이프 사이클을 적용
컨테이너 라이프 사이클 PostStart를 사용해 파드 생성 후 커맨드가 실행될 수 있도록 하고, manage.py의 initial 함수가 동작하면서 커넥터가 생성됩니다.
apiVersion: apps/v1 kind: Deployment spec: template: ... spec: containers: - env: ... image: gcr.io/soomgo/custom-connect name: connect imagePullPolicy: Always ports: - containerPort: 8083 lifecycle: postStart: exec: command: ["/bin/bash", "-c", "sleep 30 && python manage.py initial"] ...
커넥트 파드의 health check 및 셀프 힐링
커넥터 구성 컨피그를 만들고 매니페스트에서 사용할 도커 이미지를 구성한 뒤, 쿠버네티스에 배포하면 앞에서 정의해 놓은 컨피그 파일을 읽어 커넥터가 자동으로 생성되도록 개선되었습니다.
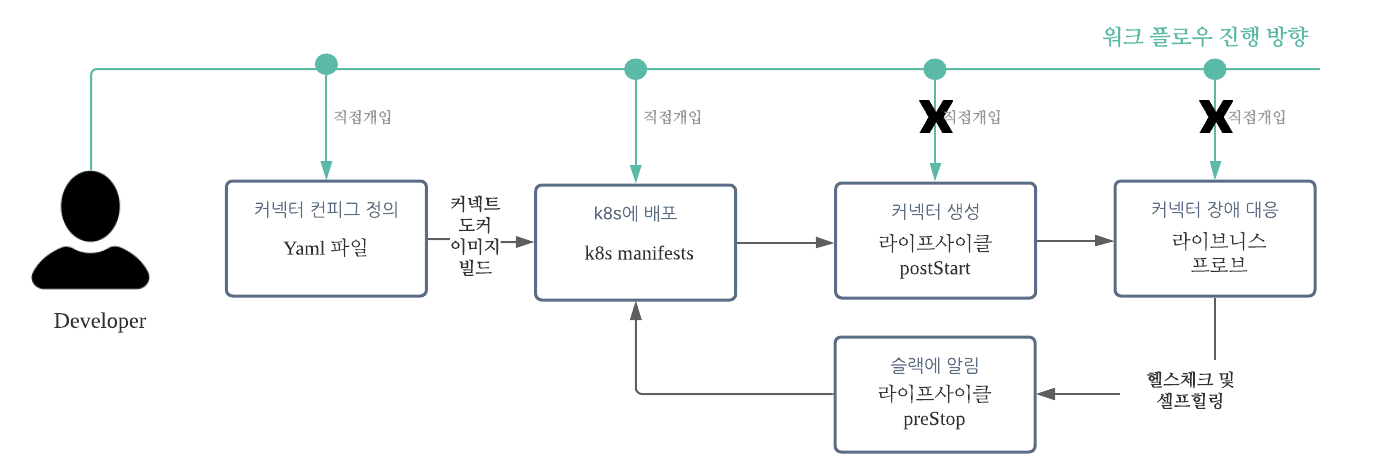
이제부터는 커넥터 파드에서 예기치 못한 상황이 발생 시에 장애 파악 및 적절한 조치를 하기 위해서는 어떤 작업을 했는지에 대해서 이야기 해보겠습니다.
(1) 라이브니스 프로브 적용을 위한 함수 추가
위에서 만들어진 manage.py에 livenessalert과 liveness 함수를 추가했습니다. 이 함수들의 목적은 파드 상태를 체크하는 것입니다. 파드 상태를 체크하기 위해서 간단한 로직을 구성해보았습니다.
liveness 함수에서는 커넥터 별 구성 정보를 명시해 놓은 컨피그 파일과 REST API를 통해 생성된 커넥터 수를 비교해서 커넥트 파드가 제대로 동작하고 있는지 체크하도록 합니다. 이때 파드 상태가 정상적이지 않으면(즉, 운영되어야 하는 커넥터와 운영하기 위해 실제로 등록된 커넥터가 다를 시)에는 livenessalert 함수로 슬랙에 알림을 보내고 있고, 파드가 재시작하는 셀프힐링을 진행하게 됩니다.
def get_connectors(self): r = requests.get(self.url) connectors = r.json() return connectors def slack_post(msg): token = 'slack-channel-token' channel = '#slack-channel' client = slack_sdk.WebClient(token=token) client.chat_postMessage(channel=channel, text=msg) @cli.command() def livenessalert(): slack_msg = f""" 커넥트 파드가 곧 재실행됩니다. """ slack_post(slack_msg) @cli.command() def liveness(): cache_file = 'cache.txt' cache_count = 0 with open(os.path.join(BASE_DIR, cache_file), 'r') as f: cache_count = int(f.read()) if cache_count == 0: cache_count += len(Connector(filename='source.yaml').get_resources()['resource']) cache_count += len(Connector(filename='sink.yaml').get_resources()['resource']) with open(os.path.join(BASE_DIR, cache_file), 'w') as f: f.write(str(cache_count)) api_connectors = len(Connector().get_connectors()) if api_connectors == 0 or api_connectors != cache_count: sys.exit(1) else: sys.exit(0)
(2) 라이브니스 프로브 적용
라이브니스 프로브와 preStop 컨테이너 라이프사이클을 적용해서 라이브니스 프로브가 동작하고, 동작시에 미리 슬랙에 알림을 줄 수 있도록 앞서 구성된 connect.yaml 매니페스트에 추가했습니다.
lifecycle: preStop: exec: command: ['/bin/sh', '-c', 'python manage.py livenessalert'] livenessProbe: exec: command: ['/bin/sh', '-c', 'python manage.py liveness'] initialDelaySeconds: 10 periodSeconds: 5 failureThreshold: 1
마치며
마지막으로 bitbucket CI/CD 파이프라인을 적용함으로써 전체적인 프로세스를 자동화했습니다. 아래의 그림이 전체적인 워크프로세스입니다. 엔지니어는 config 폴더의 sink.yaml과 source.yaml에 커넥터 구성 설정을 변경하고 bitbucket 레포지토리에 변경된 내용을 반영합니다. 그러면 CI 파이프라인에 의해서 변경 내용이 반영된 도커 이미지가 빌드되고, 빌드된 도커 이미지를 사용해 쿠버네티스에 배포됩니다.
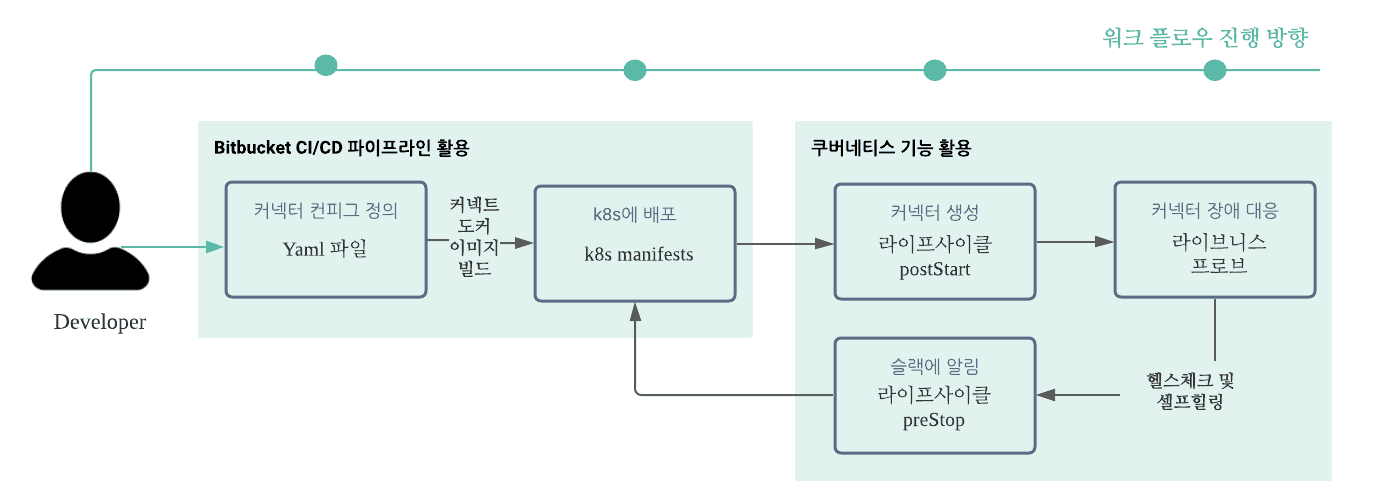
카프카 커넥트의 커넥터를 관리할 수 있는 프로세스를 구축했습니다. 아래와 같은 부분을 개선시킬 수 있었습니다.
- 카프카 시스템 배포 시, 정의한 커넥터 생성을 자동화
- 커넥터 구성 요소 관리가 수월해짐
- 예상치 못한 커넥트 파드 비정상 동작에 대비할 수 있음
숨고에서는 카프카 커넥트의 커넥터를 관리하는 프로세스를 구축함으로써 스트리밍 데이터 파이프라인의 성숙도를 높일 수 있었습니다. 앞으로도 안정적인 데이터 파이프라인을 구축하기 위해서 고민할 예정입니다. 읽어주셔서 감사합니다.
참고
- 컨플루언트 Kafka-Connect
- 컨플루언트 Kafka Connect Concept
- 디비지움 아키텍처
- 디비지움 mysql 커넥터
- CDC 오픈 소스 Debezium 쓸까? 말까?
- 쿠버네티스 컨테이너 라이프사이클 훅
- 쿠버네티스 파드 라이프사이클
- #data
- #development



