
숨고 데이터 뜯어보기: Time Series Decomposition
안녕하세요.
숨고 데이터 챕터에서 Data Scientist 로 일하고 있는 Furiosa라고 합니다.
데이터를 분석 하다 보면 다양한 원석의 데이터를 접하게 됩니다. 데이터 분석가들은 이러한 날 것의 데이터를 마주할 때 이를 어떻게 가공할까에 대해 먼저 고민합니다. 데이터를 어떻게 바라보는가에 따라 사용하는 분석 방법과 결론들이 달라지는 경우가 많기 때문입니다. 이번 글에서는 저희가 경험하였던 데이터 중 특히 숨고의 시계열 데이터를 분석해본 경험에 대해 공유하고자 합니다.
시계열 분해 모형
시계열 데이터는 간단하게 시간 순으로 나열된 숫자들입니다. 실생활에서 흔히 볼 수 있는 주식 차트나 기온, 강수량 등이 대표적인 시계열 데이터라고 볼 수 있습니다. 시계열 데이터에 포함된 각각의 숫자들은 특정 시점의 이전, 이후 데이터와 긴밀하게 영향을 주고 받습니다. 이렇게 이웃한 숫자들 사이의 상호작용을 분석하여 과거를 돌아보고 미래를 예측하는 것이 시계열 분석의 핵심입니다.
소개할 시계열 분석 기법은 시계열 분해 기법(Time Series Decomposition)이라는 방법론으로 시계열 데이터를 추세, 계절성 등의 성분으로 나눕니다. 이 기법들은 여러 파생된 버전이 있는데, 시계열에서 주로 사용되는 X-13 ARIMA, STL, 그리고 주로 예측에 사용되는 Meta의 Prophet 모델들 모두 시계열 분해 기법에 뿌리를 두고 있습니다. 이 외에도 다양한 시계열 분석 기법들이 있기에 기회가 되면 추후 다른 글에서 하나씩 다루면 좋을 것 같습니다.
보통 시계열 데이터 분해 모형이 추세, 계절성을 강조한다면 이번 모형에서는 캘린더 효과라는 항목을 추가하였고, 각각의 항을 숨고 서비스에 맞추어 구축하였습니다. 이렇게 만들어진 숨고만의 시계열 데이터 분해 모형은 아래와 같은 수식으로 표현할 수 있습니다.
각각의 성분에 대해 간단하게 설명하자면 는 일반적으로 시계열에 내재된 상승 또는 하강 흐름을 나타내는 추세, 은 보통 연 단위로 반복되는 패턴을 의미하는 계절성, 는 요일 혹은 휴일별로 반복되는 특징들을 잡아내는 캘린더 효과를 의미합니다. 이러한 분해를 통해 각각의 효과들이 특정 지표에서 차지하는 비중에 대한 보다 정확한 분석이 가능해집니다. 이를 통해서 무엇을 할 수 있는지는 아래 분석 결과에서 조금 더 자세하게 설명해보겠습니다.
이 중 가장 주안점을 둔 부분은 바로 계절성을 의미하는 항입니다. 계절성은 기후에 대한 사람들의 반응 또는 행동 패턴을 잡아내는 부분인데, 이번 모형에서는 명시적으로 기온 이라는 변수를 고려하였습니다. 는 특정 시점에 해당 기온이 발생할 확률을 나타내는 '기온 분포 함수'로, 는 기온에 대한 특정 지표의 반응도(변화율)을 나타내는 '기온 반응 함수' 입니다. 이 두 함수를 결합하면 각 기온에 따라 기대되는(expectation) 지표의 반응도를 계산할 수 있으므로 이것을 계절성이라고 보았습니다.
분석 결과
기온 반응 함수
기온 반응 함수는 추정된 추정량(estimator)을 이용하여 위와 같이 계산할 수 있는데, 이번 글에서는 유저 및 고수의 숨고 서비스 가입수(이하 '유저 가입수', '고수 가입수)를 주요 지표로 삼아 논의를 이어가도록 하겠습니다.
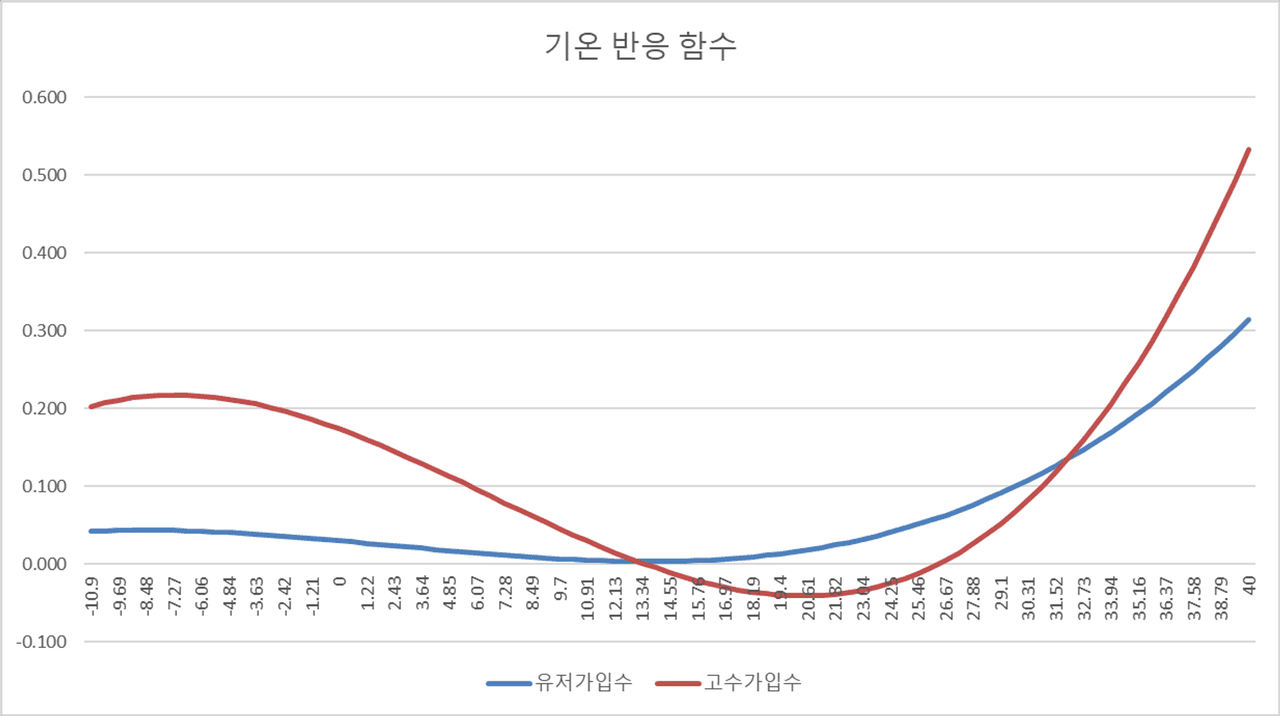
그래프의 x축은 기온 , y축은 추세 대비 변화율을 의미합니다. 예를 들어, 영상 40도에서는 계절성으로 인해 고수의 가입수가 평소보다 50% 이상 증가하는 경향을 보인다는 뜻입니다. 이 기온 반응 함수는 두 가지 특성을 갖고 있는데요. 이를 더 잘 확인하기 위해 그래프의 모양이 더 확실한 고수 가입수의 기온 반응 함수를 기준으로 설명하겠습니다.
제가 지금 이 글을 작성하고 있는 오늘의 숨고 오피스 인근 기온은 최저 5도, 최고 15도입니다. 평균 기온을 10도로 가정한다면 추세 대비 가입자수가 약 5% 정도가 계절적인 요인으로 인해서 증가한다 라고 해석할 수 있습니다. 하지만 앞으로 점차 날씨가 추워지면 어떻게 될까요? 기온이 하락함에 따라 기온 반응 함수의 기울기는 점점 가파르게 올라가고, 영하 7도에서 8도 부근에서 약 20%의 증가 추세를 보입니다. 하지만 날씨가 따뜻해지면 그래프는 하강 곡선을 그리다가 약 13도 근방에서 추세 대비 가입자수가 오히려 줄어들더니 25도를 전후로 매우 가파른 상승곡선을 그리게 됩니다.
즉, 기온 반응 함수는 여름 기온대에서의 기울기가 겨울 기온대의 기울기보다 가파른 비대칭성, 그리고 여름철과 겨울철의 기온이 1도 상승함에 따른 반응도가 선형적으로 증가하지 않고 높은, 또는 낮은 온도일수록 1도의 상승 폭이 큰 비선형성을 가집니다.
위의 두 가지 특성은 유저 가입수 그래프에서도 비슷하게 드러나지만 전체적인 그래프의 모양이 고수 가입수에 비해서는 훨씬 완만한 모습을 보입니다. 예를 들어, 고수 가입수는 13도에서 26도 사이에서는 기온에 따른 반응도가 0보다 작아졌다가 26도 이후로는 급격한 상승곡선을 그리지만, 유저 가입수는 영하 10도부터 영상 40도까지 비교적 완만하게 상승합니다. 이를 통해 우리는 고수 가입수가 유저 가입수에 비해 기온에 더 민감하게 반응하며 변동성도 훨씬 크다는 것을 알 수 있었습니다.
캘린더 효과 추정
다음으로는 캘린더 효과입니다. 캘린더 효과를 측정하기 위해 특수일을 제외한 평일(화, 수, 목의 평균)을 기준으로 높고 낮음을 확인하였으며, 기온 반응 함수와 동일하게 날짜별 유저 가입수와 고수 가입수를 지표로 삼았습니다. 이번 분석에서 고려한 특수일은 월요일과 금요일, 주말(토요일과 일요일), 새해 첫 날, 3.1절, 어린이날, 현충일, 광복절, 개천절, 한글날, 크리스마스, 임시공휴일, 선거일, 부처님오신날, 명절 연휴(설과 추석)입니다.
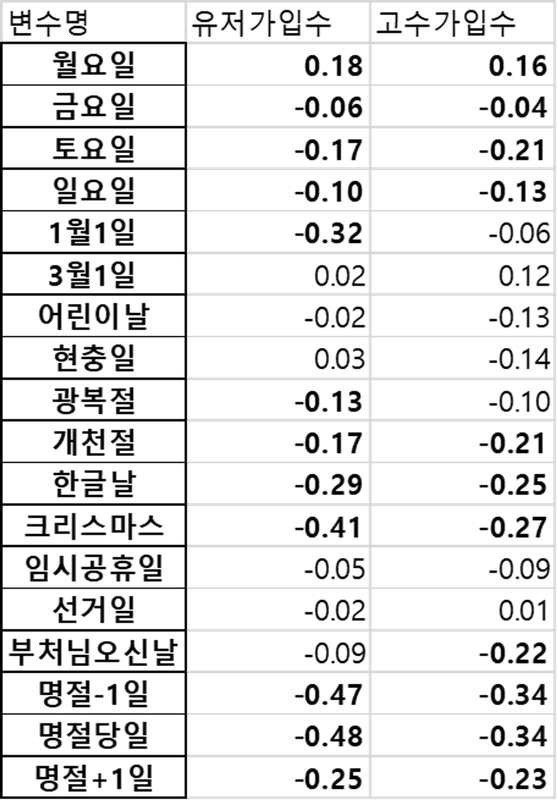
결과를 해석해보면, 먼저 월요일은 평일 대비 유저 가입수는 18%, 고수가입수는 16% 정도 높았습니다. 반대로 토요일은 유저 가입수는 17% 정도 낮았으며, 고수 가입수도 21% 가량 낮은 모습을 보였습니다. 금요일과 일요일도 각각 6%, 4%, 그리고 10%, 13%로 유저와 고수 모두에서 낮은 가입수를 보였습니다.
이와 비슷하게 각종 국경일과 공휴일에서도 평일 대비 유저와 고수 모두 가입수가 낮은 것을 확인할 수 있습니다. 통계적으로 유의한 특수일인 개천절, 한글날, 크리스마스만 보더라도 두 지표 모두에서 평일 대비 최소 17%, 최대 41%까지 낮은 가입자수를 보입니다. 또한 명절의 경우 연휴 3일 중 명절 전일과 명절 당일은 평일 대비 무려 50% 정도 수치가 낮지만, 명절 다음 날에는 일반적인 토요일에 준하는 수준으로 추정되었습니다.
다만, 일부 특수일은 캘린더 효과가 유의하게 나타나지 않았는데요. 예를 들면 선거일의 경우 5년, 또는 4년을 주기로 치뤄지기 때문에, 숨고에 쌓인 데이터만으로는 유의한 수준까지 추정하기에 어려움이 있었습니다. 임시 공휴일 또한 국경일이 휴일인 경우라는 특수한 상황에서만 발생하기 때문에 유의한 추정을 하기엔 시계열 데이터의 길이가 짧았던 것으로 추측할 수 있습니다.
유효일수
이러한 캘린더 효과의 추정 결과를 이용하면 유효일수라는 개념을 만들 수 있습니다. 유효일수에 대해 설명하기 위해 당연히 받아들였던 “하루” 라는 개념부터 이야기를 시작해보겠습니다.
흔히 생각하는 ‘하루’, 또는 ‘1일’은 어떻게 측정되는 걸까요? 조금 추상적일수도 있지만 곰곰히 생각해보면 1일은 '시간'이라는 단위로 측정한 결과물입니다. 그럼 질문을 바꿔서 만약 1일을 ‘시간’이 아니라 ‘지표’ 단위로 측정하면 어떻게 될까요? 2022년 9월을 예로 들어보겠습니다.

추석 연휴가 포함되어 있는 9월 5일부터 9월 11일을 보면, 이 주의 ‘일수’는 7일입니다. 하지만 ‘주 별 유저 가입자수’라는 지표를 기준으로 생각해보면, 평소 대비 가입자수가 작게 나올 가능성이 높습니다. 왜냐하면 추석 연휴에는 유저와 고수 모두 가입자수가 줄어드는 경향성을 보이기 때문입니다.
캘린더 효과에 따르면 월요일은 평일 대비 18% 더 높은 유저 가입자수를 기록하고 있습니다. 평일을 1로 두면, 월요일은 1.18일에 해당하는 것이죠. 반대로 추석 당일은 평일 대비 약 48% 적은 유저 가입자수의 경향성을 보이고 있기 때문에, 평일을 1일로 두면, 추석 당일은 0.52일로 볼 수 있습니다. 이것이 유저 가입자수를 지표로 한 ‘유효일수’입니다.
따라서 '유효일수'는 특정 지표에 대한 보통 값, 이번 분석에서는 화, 수, 목의 평균에 해당하는 ‘평일’이라는 개념으로 ‘1일’을 정의했을때, 특정일자의 값이 ‘1일’ 대비 얼마인지를 정의한 것입니다. 여기서는 예시를 유저 가입자수로 들었지만 매출이나 요청서, 견적서 등 숨고의 다른 지표들로도 유효일수를 측정할 수 있습니다.
유효 일수의 활용
저는 데이터 분석가의 일이 지식의 생산에서 그치는 것이 아니라 데이터를 사용하는 수 많은 사용자들에게 데이터가 의미하는 것을 전달하고, 그 결과물을 활용할 수 있도록 가이드라인을 설정해주는 영역까지라고 생각합니다. 이러한 맥락에서 유효일수를 활용하면 주별 혹은 월별 데이터를 리스케일링하여 캘린더 효과나 날짜가 가지고 있는 특수성을 제거한 보다 정확한 변화를 확인할 수 있습니다.
예를 들어, 월별 데이터를 보면 각종 지표에서 3월에 비해 2월이 다소 아쉬운 성과를 내는 경우가 많습니다. 유효일수의 관점에서 바라보지 않더라도 2월은 절대적으로 일자가 적고 3월은 일자가 상대적으로 많기 때문입니다. 휴일이 많은 5월의 경우도 2월과 마찬가지로 6월이나 4월에 비해 각종 지표가 조금씩 낮게 측정됩니다.
그렇다면 캘린더 효과나 특수일의 변동성을 제거한 지표의 추이가 궁금해졌습니다. 이는 Data Scientist로서의 호기심이기도 하지만 숨고 구성원으로서도 큰 의미를 갖습니다. 외부 변수의 오염 없이 우리가 만든 프로덕트가 얼마나 잘 성장하고 있는지를 정확하게 바라볼 수 있으니까요.
예를 들어, 2022년의 9월의 첫째 주는 7일이지만, 유효일수로 측정해보면 5.98일이 됩니다. 즉, 이 주의 데이터는 7일치의 합이 아니라 5.98일치이므로, 해당 주는 평일만으로 이루어진 7일에 비해서 유효일수가 눈에 띄게 모자라는 주가 됩니다. 따라서 해당 주의 지표, 즉 유저 가입자수를 7/5.98로 리스케일링 해볼 수 있습니다.
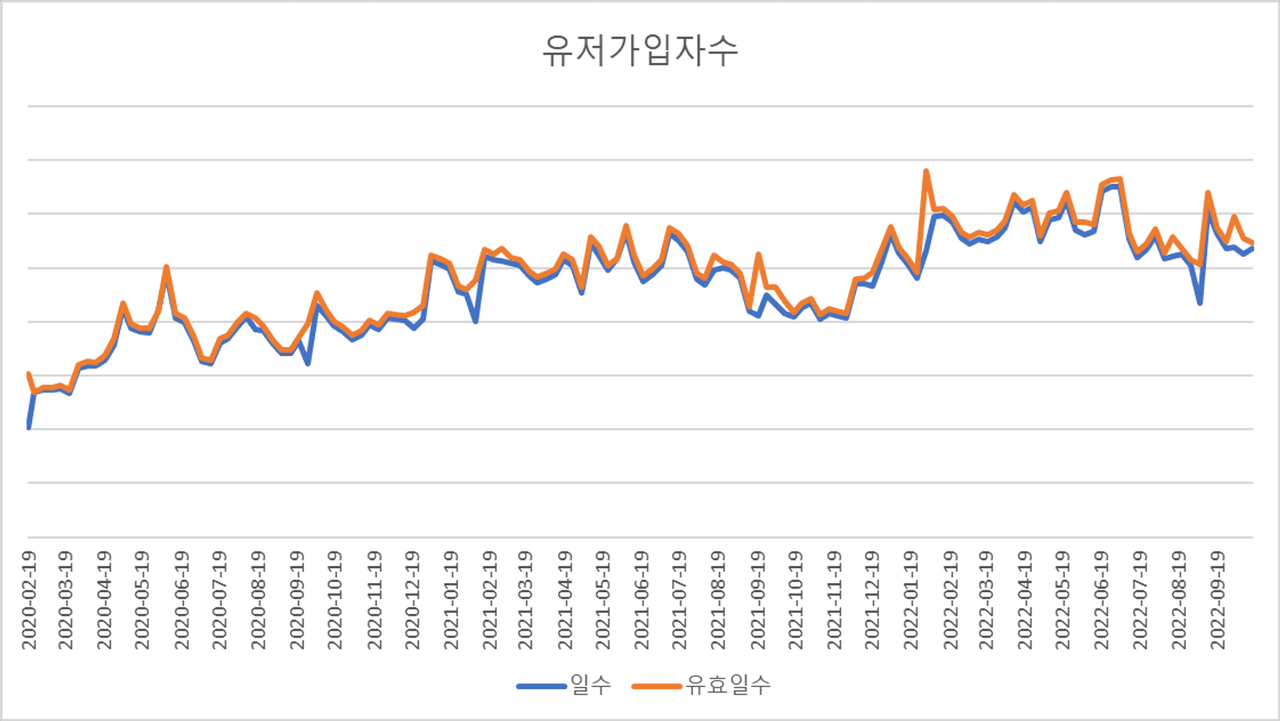
상세 수치는 대외비이기 때문에 가려두었지만 가입자수의 대략적인 추이는 확인할 수 있는데요. 숨고의 유저 가입자수는 약간의 부침은 있었지만 잘 성장하고 있는 중입니다. 원활한 비교를 위해 그래프에서 단순 주별 유저 가입자수를 파란색으로, 유효일수로 리스케일링한 데이터를 주황색으로 표시하였습니다.
이 중 유효일수에 따른 리스케일링을 잘 설명할 수 있는 지점이 설날과 추석 연휴입니다.
설날이 포함된 1월 말에서 2월 초의 경우 가입자수가 비교적 평범하게 증가한 것처럼 보이지만, 유효일수로 보면 가입자수가 눈에 띄게 증가했던 주였습니다. 캘린더 효과 추정에 따르면 명절에는 가입자수가 평일 대비 상당히 줄어들게 되는데도, 가입자수가 평일 대비 증가했기 때문에 원본 데이터보다 리스케일링한 데이터의 증가폭이 상당한 것을 확인할 수 있습니다.
이러한 가입자 수의 증가는 올해 1월에 진행되었던 TV 광고의 영향력으로 추정됩니다. 명절에는 온가족이 모여 TV를 보기 쉬운 환경이 되는 만큼, TV 광고의 노출도가 평소보다 높아져 주말과 연휴의 캘린더 효과를 상쇄하고도 남을 만큼의 효과를 보여준 것이 아닐까합니다.
반면, 9월 추석이 있었던 주는 지표의 하락을 예상하긴 했지만 예상보다 큰 폭의 하락이 있었습니다. 당시 많은 사람들이 아무리 추석이라지만 지표가 너무 많이 하락하는 것이 아닌가라는 걱정을 했었는데요. 리스케일링한 데이터를 보게 되면 평소의 주말, 연휴와 비슷한 수준의 변동성이라는 생각이 듭니다.
정확하지는 않지만 아마도 이번 추석 연휴에 주말과 임시공휴일이 포함되어 있다보니, 보통의 주말, 연휴보다 캘린더 효과가 더 크게 작용해 일종의 착시 현상을 일으킨 것으로 생각해볼 수 있습니다.
마무리하면서
이번 분석은 데이터 챕터에서 약 3개월 동안 함께 고민하며 만든 결과물로, 숨고 구성원들이 오랜 기간 동안 체감해왔던 ‘더우면 유저가 많아져요’, ‘추석 연휴때는 아무래도 매출이 줄어드네요’ 와 같은 경향성을 실제 데이터 분석을 통해 숫자로 확인해볼 수 있었습니다. 이를 통해 그동안 모두가 체감하고 있던 가설에 명확한 근거를 제시함으로써 보다 적극적인 액션 플랜을 수립할 수 있게 되었다는 측면에서 큰 의미가 있다고 생각합니다.
하지만 현재 숨고에서 분석에 필요한 시계열 데이터의 양은 많지 않습니다. 특히 이번 분석은 2020년 이후의 데이터만을 사용했기 때문에 짧은 시계열 길이라는 근본적인 한계를 가집니다. 하지만 이후 더 많은 데이터가 쌓이게 된다면 지금보다 더 정교한 분석이 가능할 것으로 기대하고 있습니다.
숨고의 데이터 챕터는 항상 더 정확하고 활용성 높은 분석을 위해 노력하고 있습니다. 이 글의 분석은 챕터 구성원들이 진행하는 멋진 일들에 일부분에 지나지 않습니다. 앞으로도 계속해서 저희의 분석 방법과 결과물들에 대해서 작성하고자 합니다. 항상 본인의 위치에서 최선을 다해준 데이터 챕터 여러분께 이 글을 빌려 진심으로 감사드립니다.
처음으로 적는 데이터 관련 글이다보니 조금 어려운 글이 된 것 같기도 합니다. 다음에는 조금 더 캐주얼하고 의미 있는 이야기들로 찾아 뵙겠습니다.
긴 글 읽어주셔서 감사합니다.
- #calendar effect
- #data
- #data analytics
- #seasonality
- #time series
- #trend



